ML OWASP Top 10
บทความนี้เรียบเรียงจากเนื้อหาใน Hack The Box Academy และปรับถ้อยคำ/โครงสร้างใหม่ให้สอดคล้องกับรายการของ OWASP Machine Learning Security Top 10 มากขึ้น เพื่อให้อ่านง่ายและใช้อ้างอิงต่อได้สะดวกขึ้น
Machine Learning Security คือเรื่องของการปกป้องระบบ ML ตั้งแต่ข้อมูลฝึกสอน ตัวโมเดล ขั้นตอน deploy ไปจนถึงผลลัพธ์ที่ผู้ใช้งานเห็นจริง ในแง่นี้มันมีความคล้ายกับ OWASP Top 10 ของฝั่งเว็บแอป คือใช้เป็นกรอบช่วยให้เราเห็น “กลุ่มความเสี่ยงหลัก” ที่พบบ่อยและควรระวัง
อย่างไรก็ตาม ML มีพื้นผิวการโจมตีมากกว่าซอฟต์แวร์ทั่วไป เพราะไม่ได้มีแค่โค้ดและเซิร์ฟเวอร์ แต่ยังรวมถึง training data, model artifacts, feedback loops, model hubs, MLOps pipeline และการตัดสินใจของคนที่เชื่อผลลัพธ์ของโมเดลมากเกินไปด้วย
บทความนี้จะพาไล่ดูภาพรวมของ ML OWASP Top 10 ทีละข้อ พร้อมตัวอย่างแบบเข้าใจง่ายว่าความเสี่ยงแต่ละแบบหน้าตาเป็นอย่างไร
ภาพรวมทั้ง 10 ข้อ
ID | รายการ | สรุปสั้น ๆ |
|---|---|---|
ML01 | Input Manipulation Attack | ปรับแต่งอินพุตเพื่อหลอกให้โมเดลทำนายผิด |
ML02 | Data Poisoning Attack | ปนเปื้อนข้อมูลฝึกสอนเพื่อทำให้โมเดลเรียนรู้ผิด |
ML03 | Model Inversion Attack | พยายามดึงข้อมูลลับย้อนกลับจากโมเดลหรือผลลัพธ์ |
ML04 | Membership Inference Attack | เดาว่าข้อมูลบางรายการเคยอยู่ในชุดฝึกสอนหรือไม่ |
ML05 | Model Theft | ขโมยหรือสร้างโมเดลเลียนแบบจากการโต้ตอบกับของจริง |
ML06 | AI Supply Chain Attacks | โจมตีผ่านโมเดล ไลบรารี dataset หรือเครื่องมือภายนอก |
ML07 | Transfer Learning Attack | แฝงปัญหาไว้ในโมเดลต้นทางที่ถูกนำไป fine-tune ต่อ |
ML08 | Model Skewing | บิดพฤติกรรมโมเดลผ่าน feedback/training distribution |
ML09 | Output Integrity Attack | แก้ไขผลลัพธ์หลังโมเดลตอบ แต่ก่อนถึงมือผู้ใช้ |
ML10 | Model Poisoning | แก้ไขน้ำหนัก/พารามิเตอร์ของโมเดลให้ทำงานผิด |
หมายเหตุ: ชื่อ ML07–ML10 ด้านบนอ้างอิงตามโครงการ OWASP Machine Learning Security Top 10 โดยตรง ซึ่งแตกต่างจากฉบับย่อ/คำเรียกแบบไม่เป็นทางการที่มักพบในสรุปหลายแห่ง
ML01: Input Manipulation Attack
การโจมตีแบบนี้คือการปรับอินพุตเพียงเล็กน้อยเพื่อหลอกให้โมเดลตัดสินใจผิด ทั้งที่สำหรับมนุษย์แล้วข้อมูลอาจดูแทบไม่ต่างจากเดิมเลย
ตัวอย่างที่คลาสสิกคือ adversarial examples เช่น การแปะสติกเกอร์บางจุดบนป้ายจราจร จนระบบของรถยนต์ไร้คนขับตีความป้าย “35” เป็น “85” หรือมองวัตถุผิดประเภท
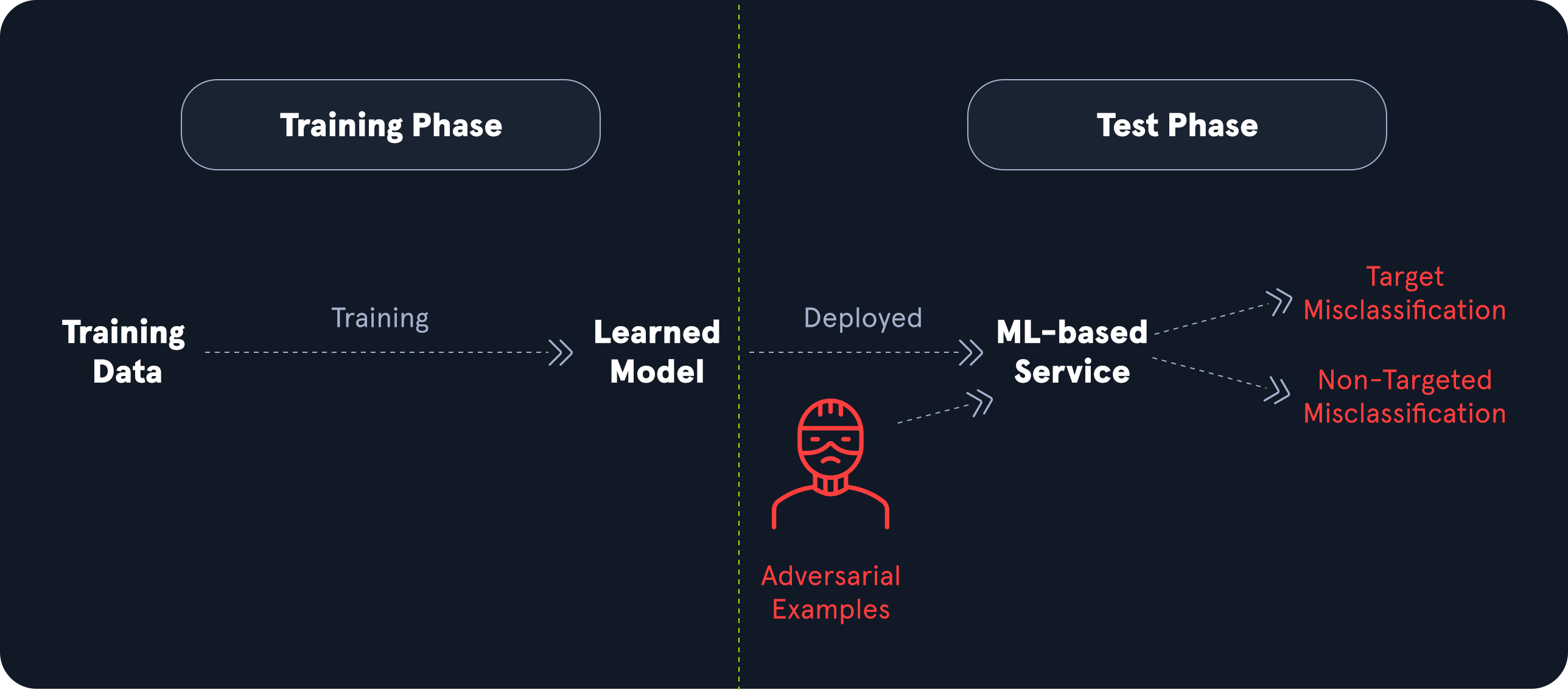
ทำไมถึงอันตราย
โมเดลอาจตัดสินใจผิดทั้งที่ข้อมูลจริงแทบไม่เปลี่ยน
กระทบระบบที่ต้องตอบสนองแบบอัตโนมัติ เช่น รถไร้คนขับ กล้องวงจรปิด หรือระบบตรวจจับการทุจริต
ผู้โจมตีอาจใช้เพื่อ bypass การตรวจจับได้โดยไม่ต้องเจาะระบบ backend โดยตรง
ตัวอย่างเข้าใจง่าย
แก้ภาพสินค้าเล็กน้อยเพื่อให้ระบบคัดกรองเนื้อหามองไม่เห็นวัตถุต้องห้าม
ปรับข้อความรีวิวหรือคำขอสินเชื่อให้หลุดจากตัวกรองความเสี่ยง
เติม noise ลงในสัญญาณเสียงเพื่อหลอก speech model
ML02: Data Poisoning Attack
นี่คือการโจมตีที่เกิดขึ้น ก่อนโมเดลจะถูกใช้งานจริง โดยผู้โจมตีทำให้ training data ปนเปื้อน ไม่ว่าจะเป็นการแทรกข้อมูลผิด ป้ายกำกับผิด หรือสร้างตัวอย่างที่มีเจตนาให้โมเดลเรียนรู้พฤติกรรมที่ไม่ต้องการ
ถ้า ML01 คือหลอกตอนใช้งาน ML02 คือทำให้โมเดล “โตมาผิด” ตั้งแต่ช่วงฝึกสอน
ตัวอย่าง
สมมติระบบกรองอีเมลสแปมเปิดรับข้อมูล feedback จากผู้ใช้จำนวนมาก ผู้โจมตีอาจส่งอีเมลสแปมจำนวนมากที่ตั้งใจทำให้ดูเหมือนอีเมลปกติ หรือทำให้ตัวอย่างสแปมถูก label ว่าเป็นอีเมลปลอดภัย เพื่อให้ระบบเรียนรู้ผิดว่ารูปแบบนั้น “ไม่น่ามีอันตราย”
ทำไมถึงอันตราย
ผลเสียฝังอยู่ในโมเดลและอาจตรวจเจอยาก
ถ้า poisoned data เข้าไปใน pipeline ได้ต่อเนื่อง ความเสียหายจะสะสม
โมเดลอาจเกิด backdoor หรือลดความแม่นยำในกลุ่มข้อมูลสำคัญโดยเฉพาะ
ML03: Model Inversion Attack
Model inversion คือความพยายามที่จะ ย้อนจากผลลัพธ์หรือพฤติกรรมของโมเดลกลับไปหาข้อมูลที่ใช้ฝึกสอนหรือข้อมูลอ่อนไหว ที่เกี่ยวข้องกับผู้ใช้จริง
แนวคิดสำคัญคือ แม้ผู้โจมตีจะไม่ได้เห็นฐานข้อมูลฝึกสอนโดยตรง แต่ถ้าโมเดลหรือ API เปิดเผยสัญญาณมากพอ ผู้โจมตีก็อาจค่อย ๆ ประกอบภาพบางส่วนกลับมาได้
ตัวอย่าง
ในระบบจดจำใบหน้า ผู้โจมตีอาจยิงคำถามเข้าโมเดลซ้ำ ๆ และใช้ผลตอบกลับเพื่อสร้างภาพประมาณการของบุคคลที่เคยอยู่ในข้อมูลฝึกสอน หรือสรุปคุณลักษณะสำคัญของกลุ่มเป้าหมายออกมา
ประเด็นที่ควรระวัง
ยิ่งโมเดลเปิดเผย confidence score หรือข้อมูลละเอียดมาก ความเสี่ยงยิ่งสูง
โมเดลที่จำข้อมูลฝึกสอนมากเกินไปมีแนวโน้มรั่วข้อมูลมากขึ้น
ปัญหานี้เชื่อมโยงกับ privacy โดยตรง โดยเฉพาะในระบบสุขภาพ การเงิน และชีวมิติ
ML04: Membership Inference Attack
ความเสี่ยงข้อนี้ไม่จำเป็นต้องดึงข้อมูลดิบออกมาทั้งก้อน แต่เน้นไปที่การตอบคำถามว่า:
“ข้อมูลชิ้นนี้เคยอยู่ใน training set ของโมเดลหรือไม่?”
แม้ดูเหมือนไม่รุนแรง แต่ในบริบทที่ข้อมูลมีความอ่อนไหวสูง แค่รู้ว่าคนคนหนึ่ง “อยู่ในชุดข้อมูลนี้” ก็อาจละเมิดความเป็นส่วนตัวได้แล้ว
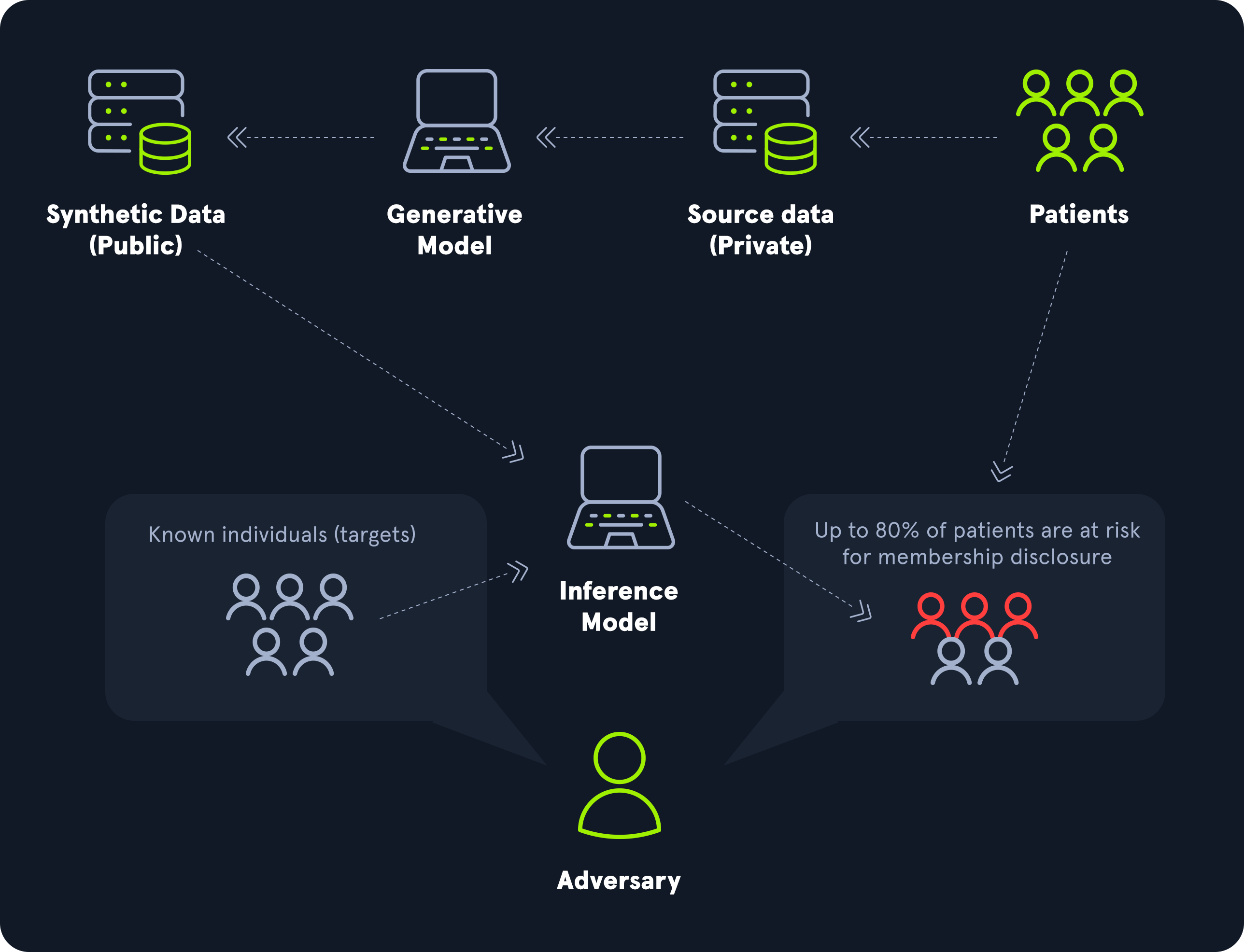
ตัวอย่าง
ถ้าโมเดลด้านสุขภาพตอบด้วยความมั่นใจสูงผิดปกติกับข้อมูลของผู้ป่วยรายหนึ่ง ผู้โจมตีอาจใช้พฤติกรรมนี้เป็นสัญญาณว่า record ของบุคคลนั้นเคยถูกใช้ฝึกโมเดลจริง
ทำไมถึงสำคัญ
กระทบ privacy และ compliance โดยตรง
ใช้ได้แม้ผู้โจมตีเข้าถึงแค่ prediction API
มักเกิดได้ดีเมื่อโมเดล overfit หรือเปิดเผย confidence มากเกินไป
ML05: Model Theft
Model theft หรือ model stealing คือการที่ผู้โจมตีพยายามขโมยคุณค่าของโมเดล ไม่ว่าจะด้วยการคัดลอกไฟล์โมเดลโดยตรง หรือสร้าง surrogate model จากการยิง query จำนวนมากแล้วเก็บผลลัพธ์กลับไปฝึกโมเดลเลียนแบบ
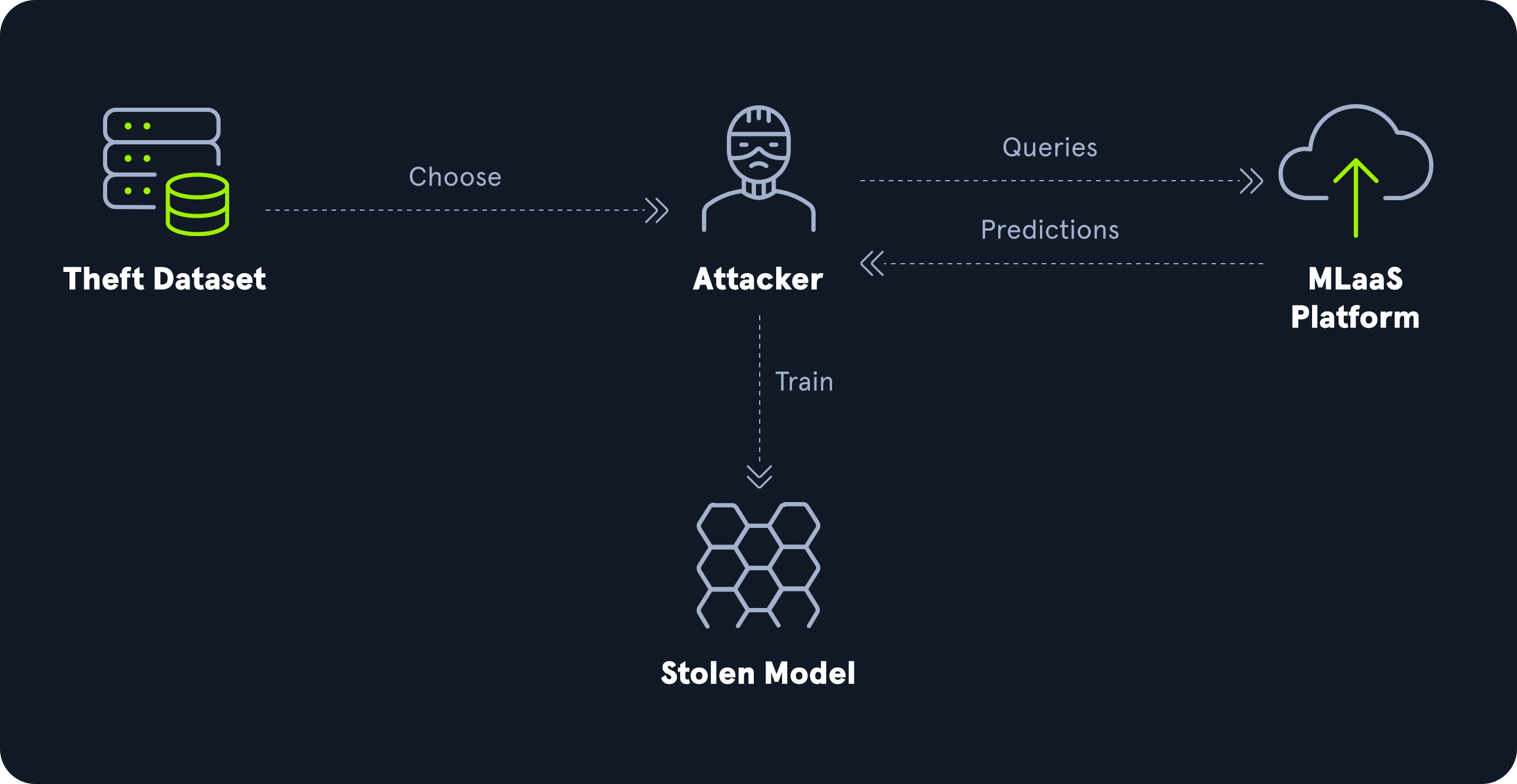
ตัวอย่าง
คู่แข่งทางธุรกิจส่งคำถามจำนวนมากเข้า API ของคุณ แล้วบันทึก input-output pair เอาไปฝึกโมเดลของตัวเอง จนมีพฤติกรรมใกล้เคียงกับของจริงโดยไม่ต้องลงทุนเก็บข้อมูลหรือวิจัยใหม่ทั้งหมด
ผลกระทบ
สูญเสียทรัพย์สินทางปัญญา
เปิดทางให้ผู้โจมตีนำโมเดลเลียนแบบไปวิเคราะห์จุดอ่อนต่อ
เพิ่มความเสี่ยงต่อการทำ evasion, inversion หรือ adversarial testing แบบออฟไลน์
ML06: AI Supply Chain Attacks
ในโลก ML เราแทบไม่เริ่มจากศูนย์ทั้งหมด เราดึง dataset, pre-trained models, notebooks, libraries, containers และเครื่องมือ MLOps จากภายนอกมาใช้เสมอ นี่ทำให้ “ห่วงโซ่อุปทาน” ของระบบ ML กว้างกว่าซอฟต์แวร์ทั่วไปมาก
ML06 จึงครอบคลุมการโจมตีผ่านองค์ประกอบเหล่านี้ เช่น
โมเดลจาก model hub ที่ถูกฝังโค้ดอันตราย
library หรือ dependency ที่ถูกแก้ไข
dataset ที่ถูกปลอมแปลงหรือแฝงข้อมูลไม่พึงประสงค์
pipeline หรือ platform ภายนอกที่ตั้งค่าผิดหรือถูกยึด
ตัวอย่าง
องค์กรดาวน์โหลดโมเดลจากแหล่งสาธารณะมาใช้งานโดยไม่ได้ตรวจสอบ provenance หรือความน่าเชื่อถือให้เพียงพอ สุดท้ายโมเดลนั้นมีโค้ดหรือ payload ที่ทำให้ข้อมูลภายในรั่วออกไปตอนโหลดใช้งาน
จุดที่คนมักมองข้าม
model artifact ก็เป็น supply chain component เช่นเดียวกับแพ็กเกจซอฟต์แวร์
notebook, conversion tool และ plugin ต่าง ๆ ก็อาจเป็นทางเข้าได้
ความเสี่ยงนี้มักเริ่มจาก “ความสะดวก” เช่น copy มาใช้ก่อน ตรวจทีหลัง
ML07: Transfer Learning Attack
ความเสี่ยงข้อนี้เกิดจากธรรมชาติของการพัฒนา ML สมัยใหม่ที่นิยมใช้ pre-trained/foundation model แล้วค่อยนำมา fine-tune ต่อกับงานเฉพาะทาง
หากโมเดลต้นทางถูกฝังพฤติกรรมไม่พึงประสงค์ไว้ตั้งแต่แรก หรือถูกทำให้มี bias/backdoor บางอย่าง ปัญหานั้นอาจติดมากับระบบปลายทางแม้ผู้พัฒนาจะคิดว่าตัวเองแค่ “โหลดโมเดลมาปรับต่อเล็กน้อย”
ตัวอย่าง
องค์กรนำโมเดล vision ที่ดาวน์โหลดมาจากภายนอกมาปรับใช้กับงานตรวจสอบคุณภาพสินค้า ภายนอกดูเหมือนโมเดลทำงานปกติ แต่เมื่อเจอลวดลายหรือ trigger บางแบบกลับจัดประเภทผิดอย่างสม่ำเสมอ
ความต่างจาก Data Poisoning
Data Poisoning เน้นปนเปื้อน training data ของระบบเรา
Transfer Learning Attack เน้นความเสี่ยงที่ติดมากับ โมเดลต้นทาง ที่เรานำมาปรับใช้ต่อ
ML08: Model Skewing
Model skewing คือการทำให้โมเดลค่อย ๆ เบี่ยงพฤติกรรมไปจากที่ควรจะเป็น ผ่านการควบคุม distribution ของข้อมูลหรือ feedback ที่ระบบใช้ในการปรับปรุงตัวเอง
ต่างจาก poisoning แบบใส่พิษชัด ๆ โมเดลอาจยังทำงาน “ดูเหมือนปกติ” อยู่พักหนึ่ง แต่ผลลัพธ์จะค่อย ๆ เอนเอียงไปในทิศทางที่ผู้โจมตีต้องการ
ตัวอย่าง
ระบบอนุมัติสินเชื่อมี feedback loop ที่ใช้ผลลัพธ์ใน production มาปรับข้อมูลฝึกสอนรอบถัดไป ผู้โจมตีแทรกข้อมูล feedback ปลอมอย่างต่อเนื่อง ทำให้โมเดลค่อย ๆ เรียนรู้ว่ากลุ่มที่มีความเสี่ยงสูงนั้นน่าเชื่อถือกว่าความจริง
ทำไมตรวจจับยาก
ความเปลี่ยนแปลงมักค่อยเป็นค่อยไป
อาจดูเหมือน data drift ตามธรรมชาติ
ถ้าไม่มี monitoring ที่ดี ทีมงานอาจสังเกตเห็นเมื่อความเสียหายเกิดขึ้นไปแล้ว
ML09: Output Integrity Attack
ข้อนี้สำคัญมากเพราะบางครั้ง ตัวโมเดลไม่ได้ผิด แต่สิ่งที่ผู้ใช้เห็นถูกแก้ไขหลังจากโมเดลตอบออกมาแล้ว
พูดง่าย ๆ คือโจมตี “ทางผ่านของคำตอบ” แทนที่จะโจมตีตัวโมเดลโดยตรง
ตัวอย่าง
AI ในโรงพยาบาลวิเคราะห์ผลแล้วระบุว่าผู้ป่วยควรได้รับการตรวจเพิ่มเติม แต่ผู้โจมตีแก้ไข output บนระบบแสดงผลให้กลายเป็นคำแนะนำว่า “ไม่พบความผิดปกติ” ทำให้แพทย์หรือเจ้าหน้าที่ตัดสินใจผิด
จุดสำคัญ
ปัญหานี้มักเกี่ยวข้องกับระบบรอบโมเดล เช่น API gateway, UI, queue, middleware หรือฐานข้อมูลผลลัพธ์
ถ้าโฟกัสแต่ model accuracy โดยไม่ป้องกัน integrity ของ output ก็ยังเสี่ยงอยู่ดี
ใช้บทเรียนเดียวกับ security ปกติได้ เช่น signing, audit logs, end-to-end integrity checks
ML10: Model Poisoning
ข้อนี้ต่างจาก Data Poisoning ตรงที่เป้าหมายอยู่ที่ ตัวโมเดลเอง เช่น การแก้ไข weights, parameters หรือ model artifact เพื่อให้โมเดลทำงานผิดจากที่ควรจะเป็น
บางกรณีอาจเกิดจากผู้โจมตีเข้าถึง environment ที่ใช้เก็บหรือ deploy โมเดล แล้วแอบสลับไฟล์หรือแก้ค่าโดยตรง
ตัวอย่าง
แฮกเกอร์เข้าถึงเซิร์ฟเวอร์ที่เก็บโมเดล production แล้วแก้ไขน้ำหนักของโมเดลตรวจจับการทุจริตให้ปล่อยผ่านธุรกรรมบางรูปแบบของตนเองโดยเฉพาะ
ต่างจาก ML08 อย่างไร
Model Skewing มักบิดพฤติกรรมผ่านข้อมูล/feedback/distribution
Model Poisoning มักแก้ไขตัวโมเดลหรือพารามิเตอร์โดยตรง
มองภาพรวมให้เข้าใจง่าย
ถ้าจะจำทั้ง 10 ข้อแบบเร็วที่สุด ให้ลองแยกตามจุดที่ถูกโจมตี:
1) โจมตีผ่านข้อมูล
ML01 หลอกอินพุตตอนใช้งาน
ML02 ปนเปื้อน training data
ML04 เดาว่าข้อมูลบางชิ้นอยู่ใน training set หรือไม่
ML08 บิด distribution/feedback ให้โมเดลเอียง
2) โจมตีผ่านตัวโมเดล
ML03 ย้อนเอาข้อมูลออกจากโมเดล
ML05 ขโมยโมเดลหรือสร้างตัวเลียนแบบ
ML07 รับโมเดลต้นทางที่มีปัญหามา fine-tune ต่อ
ML10 แก้ weights/parameters โดยตรง
3) โจมตีผ่านระบบรอบโมเดล
ML06 supply chain และส่วนประกอบภายนอก
ML09 แก้ผลลัพธ์ระหว่างทางก่อนถึงผู้ใช้
แล้วเราควรป้องกันอย่างไร
แม้แต่ละข้อจะมีรายละเอียดต่างกัน แต่หลักคิดสำคัญที่ใช้ได้แทบทุกระบบ ML คือ:
รู้ที่มาของข้อมูลและโมเดล
ตรวจสอบ provenance ของ dataset, model, library และ pipeline ให้ชัดลดการเปิดเผยที่ไม่จำเป็น
จำกัดข้อมูลที่ API ตอบกลับ เช่น confidence, logits หรือรายละเอียดเชิงลึกที่มากเกินไปเฝ้าดู drift และพฤติกรรมผิดปกติ
ทั้งด้าน data distribution, feedback loop, model performance และการใช้งาน APIแยกสิทธิ์และป้องกัน artifact
model files, checkpoints, configs และ deployment pipeline ควรได้รับการคุมสิทธิ์เหมือน secret สำคัญคิดแบบ end-to-end
อย่าดูแค่ตัวโมเดล แต่ต้องมองทั้ง input, training, serving, output, UI และคนที่เอาคำตอบไปใช้ตัดสินใจมี human-in-the-loop ในจุดสำคัญ
โดยเฉพาะ use case ที่เสี่ยงสูง เช่น สุขภาพ การเงิน กฎหมาย หรือความปลอดภัยทางกายภาพ
สรุป
ML OWASP Top 10 ช่วยให้เราเห็นว่าความเสี่ยงของระบบ Machine Learning ไม่ได้อยู่แค่เรื่อง “โมเดลแม่นหรือไม่แม่น” แต่รวมถึงความปลอดภัยของข้อมูล กระบวนการฝึกสอน ห่วงโซ่อุปทาน การ deploy และความถูกต้องของผลลัพธ์ที่ถูกส่งต่อไปใช้งานจริงด้วย
ถ้าอยากเริ่มต้นทำ ML security ให้เป็นระบบ การจำทั้ง 10 ข้อให้ได้ไม่ใช่เป้าหมายหลักเท่ากับการตอบคำถามให้ได้ว่า:
ข้อมูลของเราถูกเชื่อถือได้แค่ไหน
โมเดลที่ใช้มาจากไหนและตรวจสอบแล้วหรือยัง
pipeline มีจุดไหนที่ attacker เข้าไปแทรกได้
output ที่ผู้ใช้เห็นเป็น output จริงจากโมเดลหรือเปล่า
ทีมงานกำลังเชื่อ AI มากเกินไปหรือไม่
สุดท้าย ML security ไม่ใช่เรื่องของ data scientist หรือ security team ฝั่งใดฝั่งหนึ่งเท่านั้น แต่เป็นเรื่องร่วมกันของคนทำข้อมูล คนสร้างระบบ คนดูแล infra และคนที่ใช้ผลลัพธ์ของโมเดลตัดสินใจจริง
อ้างอิง
Hack The Box Academy: Introduction to Red Teaming AI
OWASP Machine Learning Security Top 10: https://owasp.org/www-project-machine-learning-security-top-10/
ML01 Input Manipulation Attack: https://owasp.org/www-project-machine-learning-security-top-10/docs/ML01_2023-Input_Manipulation_Attack
ML02 Data Poisoning Attack: https://owasp.org/www-project-machine-learning-security-top-10/docs/ML02_2023-Data_Poisoning_Attack
ML03 Model Inversion Attack: https://owasp.org/www-project-machine-learning-security-top-10/docs/ML03_2023-Model_Inversion_Attack
ML04 Membership Inference Attack: https://owasp.org/www-project-machine-learning-security-top-10/docs/ML04_2023-Membership_Inference_Attack
ML05 Model Theft: https://owasp.org/www-project-machine-learning-security-top-10/docs/ML05_2023-Model_Theft
ML06 AI Supply Chain Attacks: https://owasp.org/www-project-machine-learning-security-top-10/docs/ML06_2023-AI_Supply_Chain_Attacks
ML07 Transfer Learning Attack: https://owasp.org/www-project-machine-learning-security-top-10/docs/ML07_2023-Transfer_Learning_Attack
ML08 Model Skewing: https://owasp.org/www-project-machine-learning-security-top-10/docs/ML08_2023-Model_Skewing
ML09 Output Integrity Attack: https://owasp.org/www-project-machine-learning-security-top-10/docs/ML09_2023-Output_Integrity_Attack
ML10 Model Poisoning: https://owasp.org/www-project-machine-learning-security-top-10/docs/ML10_2023-Model_Poisoning